



学習目標
- オペラント条件づけを定義する
- 強化と罰の違いを説明することができる
- 強化スケジュールを区別することができる

この章の前のセクションでは、古典的条件づけとして知られる連想学習のタイプに焦点を当てました。古典的条件づけは、環境中の何かが自動的に反射を誘発し、研究者は異なる刺激に反応するように生物を訓練するものでした。ここでは、連想学習の2つ目のタイプであるオペラント条件づけについて説明します。オペラント条件づけでは、生物はある行動とその結果を関連付けることを学びます(表6.1)。快となるような結果は、その行動が将来的に繰り返される可能性を高めます。例えば、スピリットというボルチモアの国立水族館のイルカは、トレーナーが笛を吹くと空中で宙返りをします。その結果、彼女は魚を手に入れることができます。
古典的条件付けとオペラント条件づけの比較
| 古典的条件付け | オペラント条件付け | |
|---|---|---|
| 条件づけの方法 | 無条件刺激(食物など)と中性刺激(ベルなど)を対にして与える。中性刺激はやがて条件刺激となり、条件反応(唾液分泌)を引き起こす。 | 学習者が将来的に望ましい行動をとる可能性が高くなるように、目標行動の後に強化または罰を与えて、行動を強めたり弱めたりする。 |
| 刺激のタイミング | 刺激は反応の直前に起こる。 | 刺激(強化または罰)は反応のすぐ後に起こる。 |
古典的条件付けとオペラント条件付けの違い
心理学者のB.F.Skinnerは、古典的条件付けは反射的に引き出される既存の行動に限られ、自転車に乗るなどの新しい行動は説明できないと考えました。彼は、そのような行動がどのようにして起こるのかという理論を提案しました。彼は、行動は、その行動に対して得られる結果、つまり強化と罰によって動機づけられると考えました。こうしたSkinnerの考えは、心理学者Edward Thorndikeが最初に提唱した「効果の法則」に基づいています。効果の法則によると、生物にとって満足のいく結果が続く行動は繰り返されやすく、不快な結果が続く行動は繰り返されにくいとされています( Thorndike, 1911)。基本的には、ある行動が生物に望ましい結果をもたらせば、その生物は再びそれを行う可能性が高くなりますし望ましい結果をもたらさなければ、その生物が再びそれを行う可能性は低くなります。効果の法則の例としては、雇用があります。私たちが会社に出勤する理由の1つ(多くの場合、最大の理由)は、給料をもらっているからです。もし給料をもらえなくなれば、たとえ仕事が好きであっても出勤しなくなってしまうでしょう。
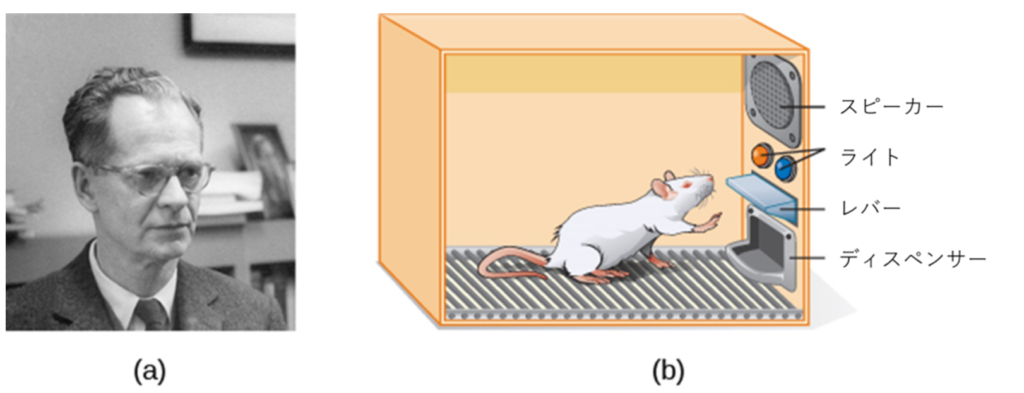
Skinnerは、 Thorndikeの「効果の法則」をもとに、動物(主にネズミとハト)を使って、オペラント条件づけによって生物がどのように学習するかを調べる科学的実験を始めました(Skinner, 1938)。Skinnerは、動物たちを「スキナー箱(オペラント実験箱)」と呼ばれるオペラント条件づけ装置の中に入れました(図6.10)。スキナー箱にはレバー(ラット用)やキー(ハト用)が入っていて、動物はそれを押したりつついたりすることで、ディスペンサーを介して餌を得ることができます。スピーカーやライトは、特定の行動と関連づけるのに用いられ、レコーダーは、動物が反応した数をカウントします。
学習へのリンク
ハトのオペラント条件付けの実演動画
オペラント条件づけについて論じるときには、正、負、強化、罰といった日常的な言葉を専門的な用法で使用します。オペラント条件づけでは、正と負は良い意味でも悪い意味でもありません。正は「何かを加えること」、負は「何かを奪うこと」を意味します。強化は「行動を増加させること」を意味し、罰は「行動を減少させること」を意味します。強化には正と負があり、罰も正と負があります。すべての強化子は、ある行動反応の可能性を高めます。すべての弱化子(罰子)は、ある行動反応の可能性を減少させます。
ここで、この4つの用語、正の強化、負の強化、正の罰、負の罰を組み合わせてみましょう(表6.2)。
| 強化 | 罰 | |
|---|---|---|
| 正 | 行動の可能性を増加させるために 何かが加えられる(提示される)。 | 行動の可能性を減少させるために 何かが加えられる( 提示される )。 |
| 負 | 行動の可能性を増加させるために 何かが取り除かれる( 除去される )。 | 行動の可能性を減少させるために 何かが取り除かれる(除去される)。 |
本記事は、OpenStaxの『Psychology 2e』の「6.3 Operant Conditioning」に基づき翻訳・改変したものです。
ライセンス: Creative Commons Attribution License v4.0
元記事(無料): https://openstax.org/details/books/psychology-2e

